在文章开头先抛几个问题:
- 什么时候才需要分库分表呢?我们的评判标准是什么?
- 一张表存储了多少数据的时候,才需要考虑分库分表?
- 数据增长速度很快,每天产生多少数据,才需要考虑做分库分表?
这些问题你都搞清楚了吗?相信看完这篇文章会有答案。
- 大量请求阻塞
在高并发场景下,大量请求都需要操作数据库,导致连接数不够了,请求处于阻塞状态。
- SQL 操作变慢
如果数据库中存在一张上亿数据量的表,一条 SQL 没有命中索引会全表扫描,这个查询耗时会非常久。
- 存储出现问题
业务量剧增,单库数据量越来越大,给存储造成巨大压力。
从机器的角度看,性能瓶颈无非就是CPU、内存、磁盘、网络这些,要解决性能瓶颈最简单粗暴的办法就是提升机器性能,但是通过这种方法成本和收益投入比往往又太高了,不划算,所以重点还是要从软件角度入手。
硬件层面主要是增加机器性能。
常常会用到 explain 这个命令来查看 SQL 语句的执行计划,通过观察执行结果很容易就知道该 SQL 语句是不是全表扫描、有没有命中索引。
ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)
ALL 代表这条 SQL 语句全表扫描了,需要优化。一般来说需要达到range 级别及以上。
但是随着业务量增加,订单表和用户表肯定也是暴增,这时候通过两个表关联数据就比较费力了,为了取一个昵称字段而不得不关联查询几十上百万的用户表,其速度可想而知。
这个时候可以尝试将 nickname 这个字段加到 order 表中(order_id、user_id、nickname),这种做法通常叫做数据库表冗余字段。这样做的好处展示订单列表时不需要再关联查询用户表了。
冗余字段的做法也有一个弊端,如果这个字段更新会同时涉及到多个表的更新,因此在选择冗余字段时要尽量选择不经常更新的字段。
如果读实例压力依然很大,可以在数据库前面加入缓存如 redis,让请求优先从缓存取数据减少数据库访问。
缓存分担了部分压力后,数据库依然是瓶颈,这个时候就可以考虑分库分表的方案了,后面会详细介绍。
硬件成本非常高,一般来说不可能遇到数据库性能瓶颈就去升级硬件。
在前期业务量比较小的时候,升级硬件数据库性能可以得到较大提升;但是在后期,升级硬件得到的收益就不那么明显了。

如上图,商城系统包括主页 Portal 模板、用户模块、订单模块、库存模块等,所有的模块都共有一个数据库,通常数据库中有非常多的表。
因为用户量不大,这样的架构在早期完全适用,开发者可以拿着 demo到处找(骗)投资人。
一旦拿到投资人的钱,业务就要开始大规模推广,同时系统架构也要匹配业务的快速发展。
第一个阶段将商城系统单体架构按照功能模块拆分为子服务,比如:Portal 服务、用户服务、订单服务、库存服务等。
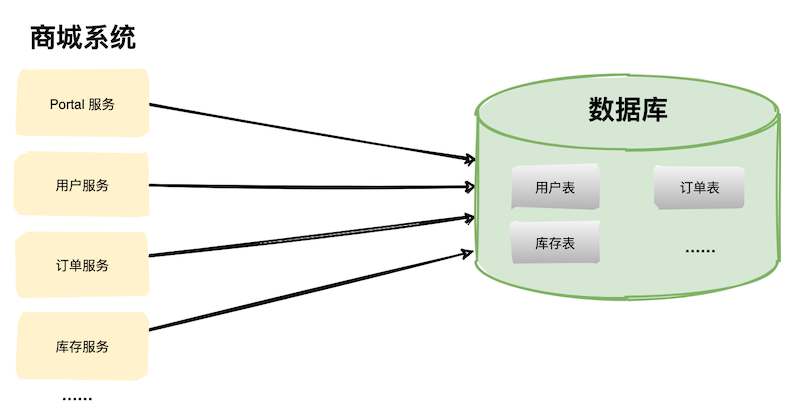
如上图,多个服务共享一个数据库,这样做的目的是底层数据库访问逻辑可以不用动,将影响降到最低。
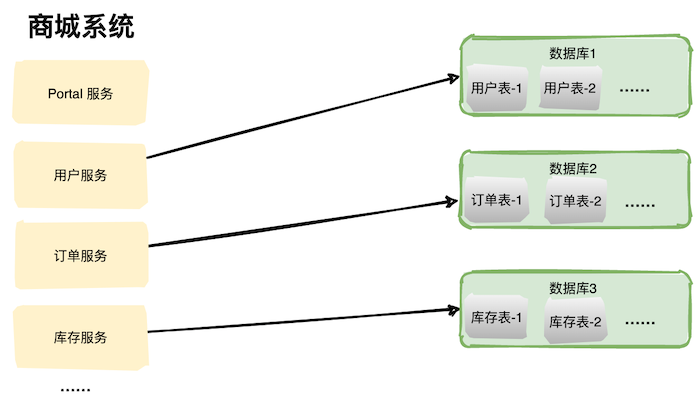
单数据库的能够支撑的并发量是有限的,拆成多个库可以使服务间不用竞争,提升服务的性能。

如上图,从一个大的数据中分出多个小的数据库,每个服务都对应一个数据库,这就是系统发展到一定阶段必要要做的“分库”操作。
现在非常火的微服务架构也是一样的,如果只拆分应用不拆分数据库,不能解决根本问题,整个系统也很容易达到瓶颈。
因此,当单表数据增量过快,业界流传是超过500万的数据量就要考虑分表了。当然500万只是一个经验值,大家可以根据实际情况做出决策。
那如何分表呢?
分表有几个维度,一是水平切分和垂直切分,二是单库内分表和多库内分表。
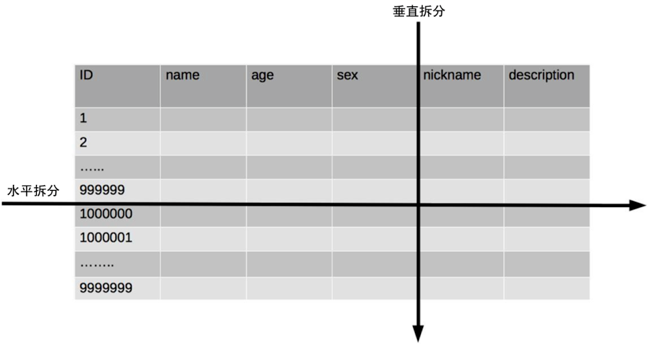
还有一种拆分方法,比如表中有一万条数据,我们拆分为两张表,id 为奇数的:1,3,5,7……放在 user1, id 为偶数的:2,4,6,8……放在 user2中,这样的拆分办法就是水平拆分了。
水平拆分的方式也很多,除了上面说的按照 id 拆表,还可以按照时间维度取拆分,比如订单表,可以按每日、每月等进行拆分。
- 每日表:只存储当天的数据。
- 每月表:可以起一个定时任务将前一天的数据全部迁移到当月表。
- 历史表:同样可以用定时任务把时间超过 30 天的数据迁移到 history表。
总结一下水平拆分和垂直拆分的特点:
- 垂直切分:基于表或字段划分,表结构不同。
- 水平切分:基于数据划分,表结构相同,数据不同。
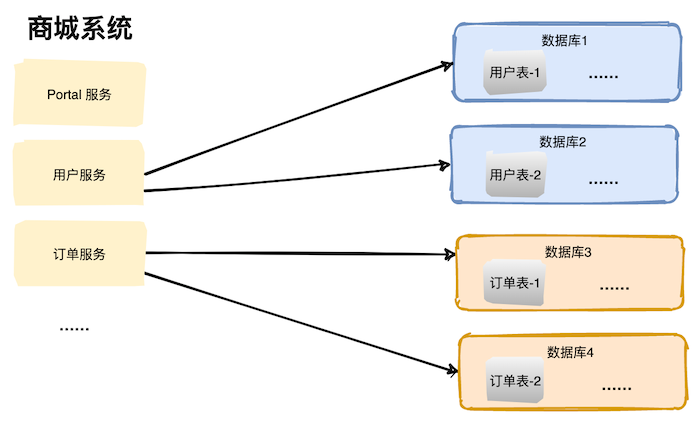
在一个数据库中将一张表拆分为几个子表在一定程度上可以解决单表查询性能的问题,但是也会遇到一个问题:单数据库存储瓶颈。
所以在业界用的更多的还是将子表拆分到多个数据库中。比如下图中,用户表拆分为两个子表,两个子表分别存在于不同的数据库中。
一句话总结:分表主要是为了减少单张表的大小,解决单表数据量带来的性能问题。
有几种方案可以解决:
- 字段冗余:把需要关联的字段放入主表中,避免 join 操作;
- 数据抽象:通过ETL等将数据汇合聚集,生成新的表;
- 全局表:比如一些基础表可以在每个数据库中都放一份;
- 应用层组装:将基础数据查出来,通过应用程序计算组装;
常用的分布式 ID 解决方案有:
- UUID
- 基于数据库自增单独维护一张 ID表
- 号段模式
- Redis 缓存
- 雪花算法(Snowflake)
- 百度uid-generator
- 美团Leaf
- 滴滴Tinyid
这些方案后面会写文章专门介绍,这里不再展开。
- shardingsphere(前身 sharding-jdbc)
- Mycat
