Warning: "continue" targeting switch is equivalent to "break". Did you mean to use "continue 2"? in /home/vhosts/www.guoyanbin.com/wp-includes/pomo/plural-forms.php on line 210 架构 | AI Site
Technologies and operational systems in businesses tend to evolve every 6 months. Certainly, matching up with the market trend every time there’s a turn is a humongous task. Imagine how much cost and effort would be saved if they were auto-scalable.
While there are many ways to enhance the scalability of a system, this article will talk about AWS serverless technology that is known to take businesses to a new level of productivity and scalability. The next big question that arises here is why is it called serverless? There are servers in the serverless but the term is used because it describes the customer’s experience of the servers, which is invisible and is not present physically in front of the customers. The customer doesn’t have to manage them or interact with them in any way.
We can dive deeper only after we have understood the true meaning of serverless computing.
What Is Serverless Computing?
It is a cloud computing execution model that provisions computing resources on demand. It enables the offloading of all common infrastructure management tasks such as patching, provisioning, scheduling, and scaling to cloud providers and tools, allowing engineers to focus on the customization required for applications required for the client.
Features of serverless computing
It does not require monitoring and management, which helps developers more time to optimize codes and find out innovative ideas to add features and functionalities to the application.
Serverless computing runs codes on-demand only, typically in a stateless container only when there’s a request. The scaling too is transparent with the number of requests being served.
Serverless computing charges only for what’s being used and not for idle capacity.
Benefits of Serverless Computing
The serverless market is estimated to grow around $20B USD by 2025. The striking figures are owed to the innumerable disadvantages of serverless computing as compared to traditional cloud computing, server-centric infrastructure. Below mentioned are some of the important benefits offered by top serverless cloud computing service providers.
No worries about server maintenance
Managed by the vendors completely, this can reduce the investment necessary in DevOps. This not just lowers the expenses but also frees up developers to create and expand the applications without being held behind by server capacity.
Codes can be used to reduce latency
Since the application is not hosted on an original server, its code can be run from anywhere. Depending on the servers, it can thus be used to run applications on servers that are close to the end-users. This reduces latency because requests from the user no longer have to travel all the way to the origin server.
Serverless architecture is scalable
Applications built on serverless architecture scale up automatically during spike season and scale down during the lean period. Additionally, if the function needs to be run in multiple instances, the vendor’s server will start, run and end when the requirement is over. This is done often using containers. A serverless application, thus, can handle a high number of requests as well as single requests.
Quick deployments are possible
There is no need for the developer to upload codes or do any backend configuration in order to release a working application. Uploading bits of code all at a time or one function at a time can help release an application quickly. This can be done because the application is not a single monolithic stack but rather a collection of functions provisioned by the vendor. This also helps in patching, fixing, updating new features to an application.
They are fault-tolerant
It is not the responsibility of the developers to ensure the fault tolerance of the serverless architecture. The cloud provider assigns the IT infrastructure that will be automatically allocated to account for any kind of failure.
No upfront costs
Users need to pay only for the running code and there are no upfront costs involved while deploying the serverless cloud infrastructure to build an application.
Why Would You Need Help?
Every technology has its own set of drawbacks which needs expert consultation and technology expertise. Some of the disadvantages of using serverless applications are as follows:
Debugging and testing become tough
It is difficult to replicate the serverless environment in order to check for bugs and see how the code will perform once deployed. Debugging is extremely difficult because developers are not aware of the backend process. Moreover, applications here are broken up into separate, smaller functions.
Solution: Businesses planning to use serverless applications should look for serverless cloud infrastructure providers of vendors who are experts in sandbox technology who can help in reducing the difficulties in testing and debugging.
Be prepared for a new set of security concerns
When applications are run on serverless platforms, the developers do not have access to the security systems or might not be able to supervise the security systems, which could be a big issue for platforms handling crucial and secret data. Since companies do not have their own assigned servers, serverless providers will often be running code from several of their customers. This scenario is also known as multitenancy. Interestingly, if not performed properly, this can lead to data exposure.
Solutions: Software service providers that sandbox functions avoid the impacts of multi-tenancy. They also have a powerful infrastructure that avoids data leaks.
Not best for long-term processes
Most of the applications do not fit the bill because clients would want a long-standing application, which would charge more on serverless architecture than on traditional ones. This is because providers charge for only the time when the code is running.
Solution: IT consultancy can help businesses understand whether their business requirements will be fulfilled by serverless architectures or not. It is advisable to get IT consultants cum solution providers to help businesses get the right guidance. This will not just save money but also time for businesses.
Risk of cold-start
Since the servers are not constantly used, the code might require ‘boot up’ when it is used. This startup might affect the performance of the application. But if the code is used regularly, the serverless provider is responsible to keep it ready for whenever it needs to be activated. A request for this ready-to-go code is called a “warm start”.
Solution: Experienced serverless cloud service providers will be able to avoid the cold start by using the Chrome V8 engine, which can restart the application in less than 5 milliseconds. The experts having good exposure to such a setup can easily manage the performance lag without the customers even noticing.
Type-set applications
Serverless cloud applications are often branded as type-set, unable to sync in with another vendor in time of transition. This is because the architecture and the workflow vary from one vendor to another.
Solution: Expert service providers can help you migrate with applications written with JavaScripts, written against the widely used service workers API. This helps in fast and seamless integrations without errors and failures.
Moving to serverless? Get the best help you need from trained developers and expert cloud consultants. Learn all about data pipeline architecture and sync serverless deployments while speeding migration times and reducing costs.
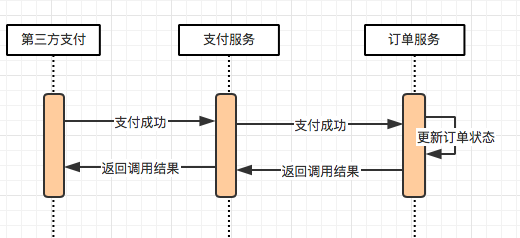
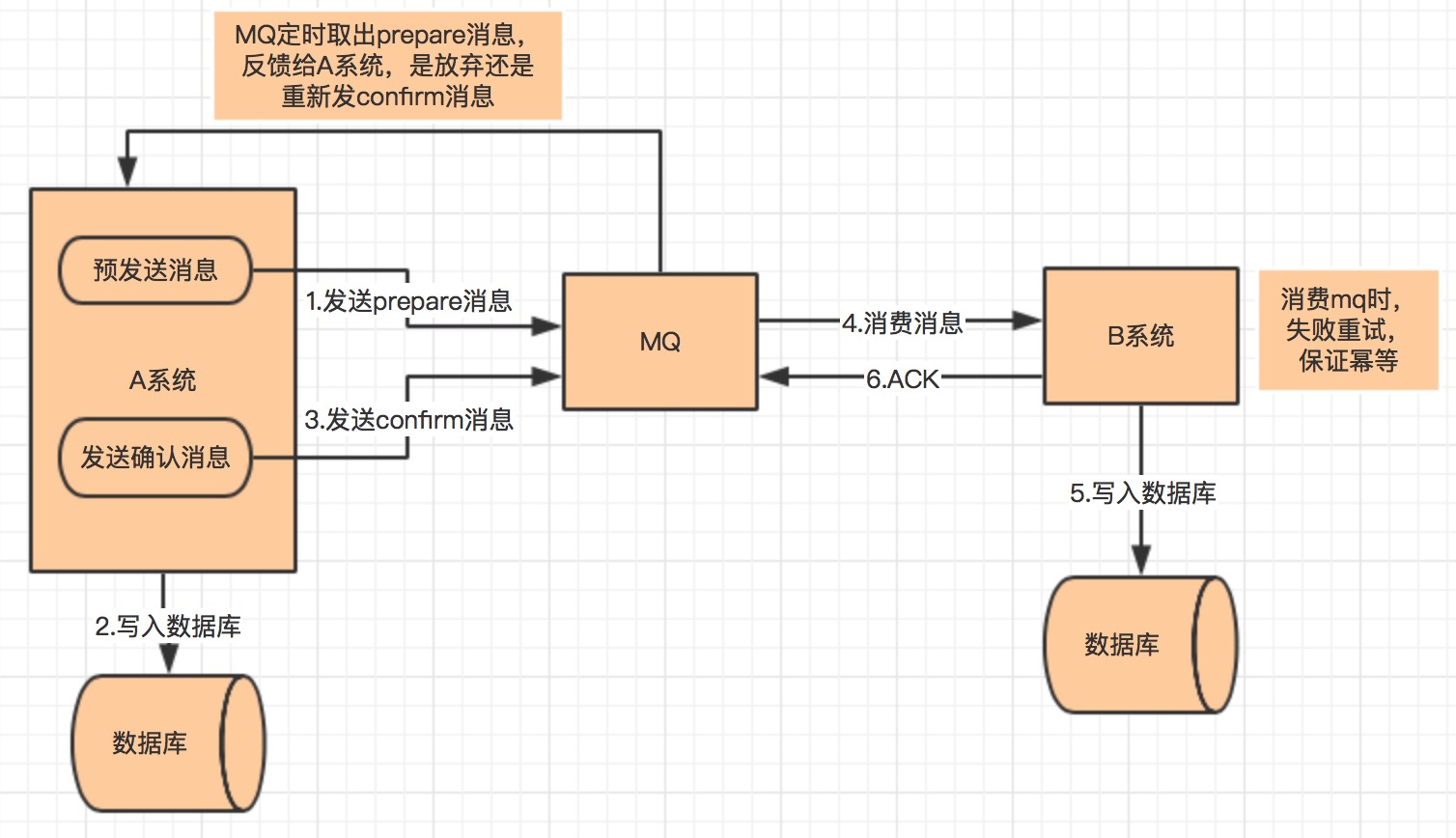
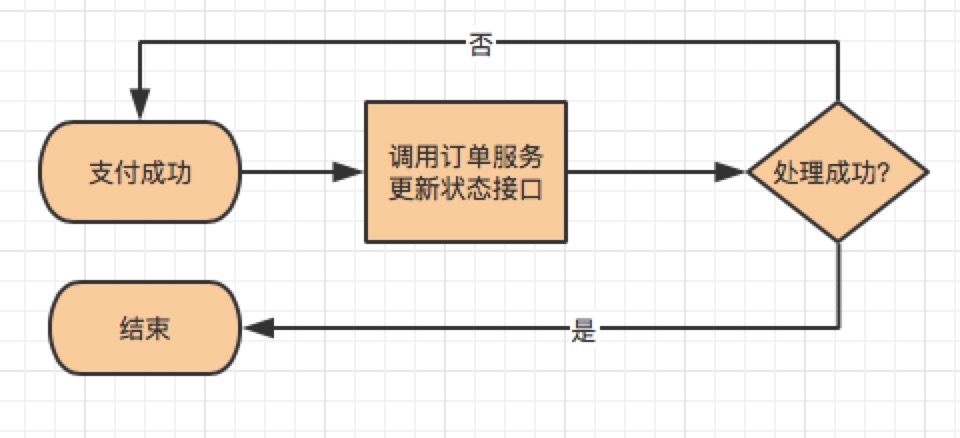
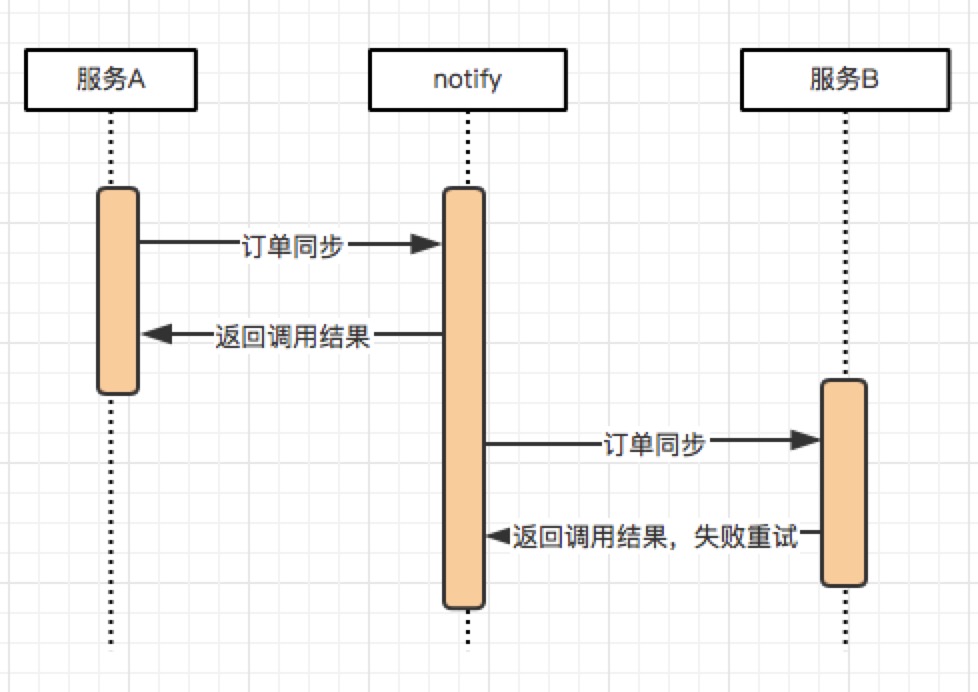
消息中间件是分布式系统常用的组件,无论是异步化、解耦、削峰等都有广泛的应用价值。我们通常会认为,消息中间件是一个可靠的组件——这里所谓的可靠是指,只要我把消息成功投递到了消息中间件,消息就不会丢失,即消息肯定会至少保证消息能被消费者成功消费一次,这是消息中间件最基本的特性之一,也就是我们常说的“AT LEAST ONCE”,即消息至少会被“成功消费一遍”。
但无论是select for update, 还是乐观锁这种解决方案,实际上都是基于业务表本身做去重,这无疑增加了业务开发的复杂度, 一个业务系统里面很大部分的请求处理都是依赖MQ的,如果每个消费逻辑本身都需要基于业务本身而做去重/幂等的开发的话,这是繁琐的工作量。本文希望探索出一个通用的消息幂等处理的方法,从而抽象出一定的工具类用以适用各个业务场景。
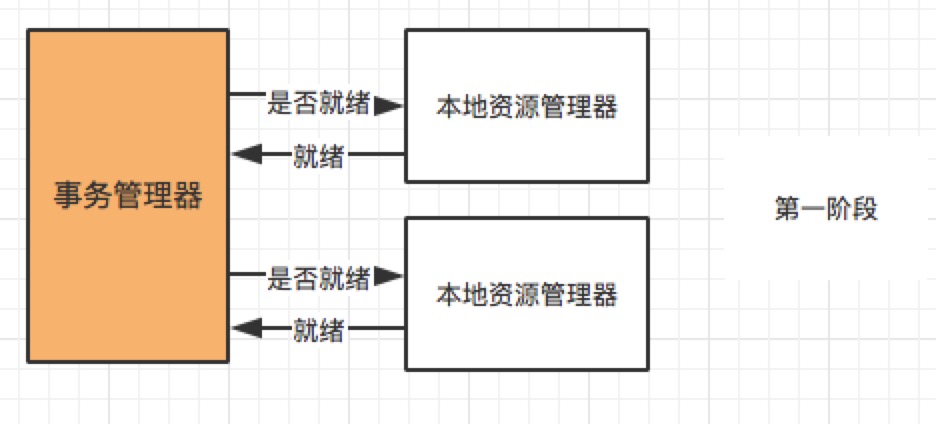
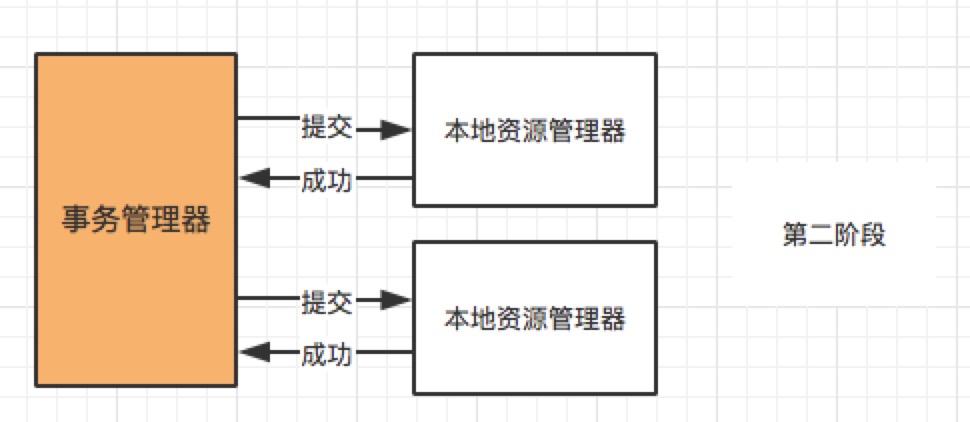
分布式事务是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。例如在大型电商系统中,下单接口通常会扣减库存、减去优惠、生成订单 id, 而订单服务与库存、优惠、订单 id 都是不同的服务,下单接口的成功与否,不仅取决于本地的 db 操作,而且依赖第三方系统的结果,这时候分布式事务就保证这些操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
CAP 原则又称 CAP 定理,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
一致性(C):
在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
可用性(A):
在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
分区容错性(P):
以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在 C 和 A 之间做出选择。
CAP 原则的精髓就是要么 AP,要么 CP,要么 AC,但是不存在 CAP。如果在某个分布式系统中数据无副本, 那么系统必然满足强一致性条件, 因为只有独一数据,不会出现数据不一致的情况,此时 C 和 P 两要素具备,但是如果系统发生了网络分区状况或者宕机,必然导致某些数据不可以访问,此时可用性条件就不能被满足,即在此情况下获得了 CP 系统,但是 CAP 不可同时满足。
BASE 理论
BASE 理论指的是基本可用 Basically Available,软状态 Soft State,最终一致性 Eventual Consistency,核心思想是即便无法做到强一致性,但应该采用适合的方式保证最终一致性。
BASE,Basically Available Soft State Eventual Consistency 的简写:
BA:Basically Available 基本可用,分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。
S:Soft State 软状态,允许系统存在中间状态,而该中间状态不会影响系统整体可用性。
E:Consistency 最终一致性,系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
BASE 理论本质上是对 CAP 理论的延伸,是对 CAP 中 AP 方案的一个补充。
柔性事务
不同于 ACID 的刚性事务,在分布式场景下基于 BASE 理论,就出现了柔性事务的概念。要想通过柔性事务来达到最终的一致性,就需要依赖于一些特性,这些特性在具体的方案中不一定都要满足,因为不同的方案要求不一样;但是都不满足的话,是不可能做柔性事务的。
转账是最经典那的分布式事务场景,假设用户 A 使用银行 app 发起一笔跨行转账给用户 B,银行系统首先扣掉用户 A 的钱,然后增加用户 B 账户中的余额。此时就会出现 2 种异常情况:1. 用户 A 的账户扣款成功,用户 B 账户余额增加失败 2. 用户 A 账户扣款失败,用户 B 账户余额增加成功。对于银行系统来说,以上 2 种情况都是不允许发生,此时就需要分布式事务来保证转账操作的成功。
下单扣库存
在电商系统中,下单是用户最常见操作。在下单接口中必定会涉及生成订单 id, 扣减库存等操作,对于微服务架构系统,订单 id 与库存服务一般都是独立的服务,此时就需要分布式事务来保证整个下单接口的成功。
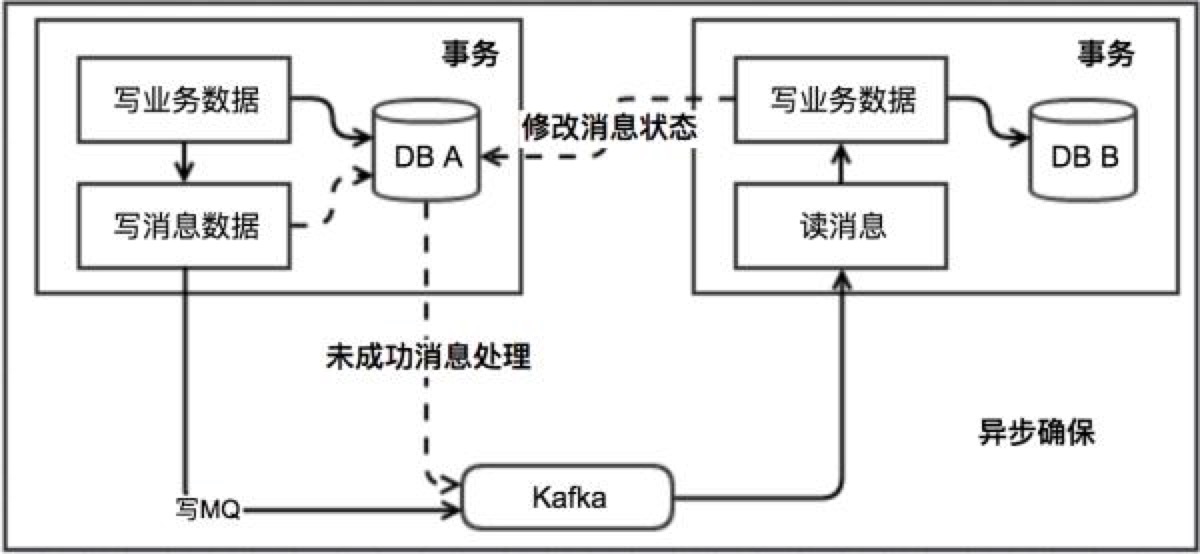
跨行转账可通过该方案实现。
用户 A 向用户 B 发起转账,首先系统会扣掉用户 A 账户中的金额,将该转账消息写入消息表中,如果事务执行失败则转账失败,如果转账成功,系统中会有定时轮询消息表,往 mq 中写入转账消息,失败重试。mq 消息会被实时消费并往用户 B 中账户增加转账金额,执行失败会不断重试。