这是 Google 的 Go 团队技术主管经理 Sameer Ajmani 分享的 PPT,为 Java 程序员快速入门 Go 而准备的。
视频
这个 PPT 是 2015年4月23日在 NYJavaSIG 中使用的。
主要内容
1. Go 是什么,谁在使用 Go?
2. 比较 Go 和 Java
3. 代码示例
4. 并发
5. 工具
Go 是什么?
“Go 是开源的编程语言,可以很简单的构建简单,可靠和高效的软件。”
Go 的历史
从 2007 后半年开始设计
- Robert Griesemer, Rob Pike 和 Ken Thompson.
- Ian Lance Taylor 和 Russ Cox
从 2009 年开始开源,有一个非常活跃的社区。
Go 语言稳定版本 Go 1 是在 2012 年早期发布的。
为什么有 Go?
Go 是解决 Google 规模的一个解决方案。
系统规模
- 规划的规模为 10⁶⁺ 台机器
- 每天在几千台机器上作业
- 在系统中与其他作业进行协作,交互
- 同一时间进行大量工作
解决方案:对并发的支持非常强大
第二个问题:工程规模
在 2011 年
- 跨 40+ 办公室的 5000+ 名开发者
- 每分钟有 20+ 修改
- 每个月修改 50% 的代码基础库
- 每天执行 5千万的测试用例
- 单个代码树
解决方案:为大型代码基础库而设计的语言
谁在 Google 使用 Go?
大量的项目,几千位 Go 程序员,百万行的 Go 代码。
公开的例子:
- 移动设备的 Chrome SPDY 代理
- Chrome, ChromeOS, Android SDK, Earth 等等的下载服务器
- YouTube Vitess MySQL 均衡器
主要任务是网络服务器,但是这是通用的语言。
除了 Google 还有谁在使用 Go?
Apcera, Bitbucket, bitly, Canonical, CloudFlare, Core OS, Digital
Ocean, Docker, Dropbox, Facebook, Getty Images, GitHub, Heroku, Iron.io,
Kubernetes, Medium, MongoDB services, Mozilla services, New York Times,
pool.ntp.org, Secret, SmugMug, SoundCloud, Stripe, Square, Thomson
Reuters, Tumblr, …
比较 Go 和 Java
Go 和 Java 有很多共同之处
- C 系列 (强类型,括号)
- 静态类型
- 垃圾收集
- 内存安全 (nil 引用,运行时边界检查)
- 变量总是初始化 (zero/nil/false)
- 方法
- 接口
- 类型断言 (实例)
- 反射
Go 与 Java 的不同之处
- 代码程序直接编译成机器码,没有 VM
- 静态链接二进制
- 内存布局控制
- 函数值和词法闭包
- 内置字符串 (UTF-8)
- 内置泛型映射和数组/片段
- 内置并发
Go 特意去掉了大量的特性
- 没有类
- 没有构造器
- 没有继承
- 没有 final
- 没有异常
- 没有注解
- 没有自定义泛型
为什么 Go 要省去那些特性?
代码清晰明了是首要的
当查看代码时,可以很清晰的知道程序将会做什么
当编写代码的时候,也可以很清晰的让程序做你想做的
有时候这意味着编写出一个循环而不是调用一个模糊的函数。
(不要变的太枯燥)
详细的设计背景请看:
- Less is exponentially more (Pike, 2012)
- Go at Google: Language Design in the Service of Software Engineering (Pike, 2012)
示例
Java程序猿对Go应该很眼熟
Main.java
public class Main {
public static void main(String[] args) {
System.out.println("Hello, world!");
}
}
hello.go
package main
import "fmt"
func main() {
fmt.Println("Hello, 世界!")
}
Hello, web server(你好,web服务)
package main
import (
"fmt"
"log"
"net/http"
)
func main() {
http.HandleFunc("/hello", handleHello)
fmt.Println("serving on http://localhost:7777/hello")
log.Fatal(http.ListenAndServe("localhost:7777", nil))
}
func handleHello(w http.ResponseWriter, req *http.Request) {
log.Println("serving", req.URL)
fmt.Fprintln(w, "Hello, 世界!")
}
(访问权限)类型根据变量名来声明。
公共变量名首字大写,私有变量首字母小写。
示例:Google搜索前端
func main() {
http.HandleFunc("/search", handleSearch)
fmt.Println("serving on http://localhost:8080/search")
log.Fatal(http.ListenAndServe("localhost:8080", nil))
}
// handleSearch handles URLs like "/search?q=golang" by running a
// Google search for "golang" and writing the results as HTML to w.
func handleSearch(w http.ResponseWriter, req *http.Request) {
请求验证
func handleSearch(w http.ResponseWriter, req *http.Request) {
log.Println("serving", req.URL)
// Check the search query.
query := req.FormValue("q")
if query == "" {
http.Error(w, `missing "q" URL parameter`, http.StatusBadRequest)
return
}
FormValueis 是 *http.Request 的一个方法:
package http
type Request struct {...}
func (r *Request) FormValue(key string) string {...}
query := req.FormValue(“q”)初始化变量query,其变量类型是右边表达式的结果,这里是string类型.
取搜索结果
// Run the Google search.
start := time.Now()
results, err := Search(query)
elapsed := time.Since(start)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
Search方法有两个返回值,分别为结果results和错误error.
func Search(query string) ([]Result, error) {...}
当error的值为nil时,results有效。
type error interface {
Error() string // a useful human-readable error message
}
Error类型可能包含额外的信息,可通过断言访问。
渲染搜索结果
// Render the results.
type templateData struct {
Results []Result
Elapsed time.Duration
}
if err := resultsTemplate.Execute(w, templateData{
Results: results,
Elapsed: elapsed,
}); err != nil {
log.Print(err)
return
}
结果results使用Template.Execute生成HTML,并存入一个io.Writer:
type Writer interface {
Write(p []byte) (n int, err error)
}
http.ResponseWriter实现了io.Writer接口。
Go变量操作HTML模板
// A Result contains the title and URL of a search result.
type Result struct {
Title, URL string
}
var resultsTemplate = template.Must(template.New("results").Parse(`
<html>
<head/>
<body>
<ol>
{{range .Results}}
<li>{{.Title}} - <a href="{{.URL}}">{{.URL}}</a></li>
{{end}}
</ol>
<p>{{len .Results}} results in {{.Elapsed}}</p>
</body>
</html>
`))
请求Google搜索API
func Search(query string) ([]Result, error) {
// Prepare the Google Search API request.
u, err := url.Parse("https://ajax.googleapis.com/ajax/services/search/web?v=1.0")
if err != nil {
return nil, err
}
q := u.Query()
q.Set("q", query)
u.RawQuery = q.Encode()
// Issue the HTTP request and handle the response.
resp, err := http.Get(u.String())
if err != nil {
return nil, err
}
defer resp.Body.Close()
defer声明使resp.Body.Close运行在Search方法返回时。
解析返回的JSON数据到Go struct类型
developers.google.com/web-search/docs/#fonje
var jsonResponse struct {
ResponseData struct {
Results []struct {
TitleNoFormatting, URL string
}
}
}
if err := json.NewDecoder(resp.Body).Decode(&jsonResponse); err != nil {
return nil, err
}
// Extract the Results from jsonResponse and return them.
var results []Result
for _, r := range jsonResponse.ResponseData.Results {
results = append(results, Result{Title: r.TitleNoFormatting, URL: r.URL})
}
return results, nil
}
这就是它的前端
所有引用的包都来自标准库:
import ( "encoding/json" "fmt" "html/template" "log" "net/http" "net/url" "time" )
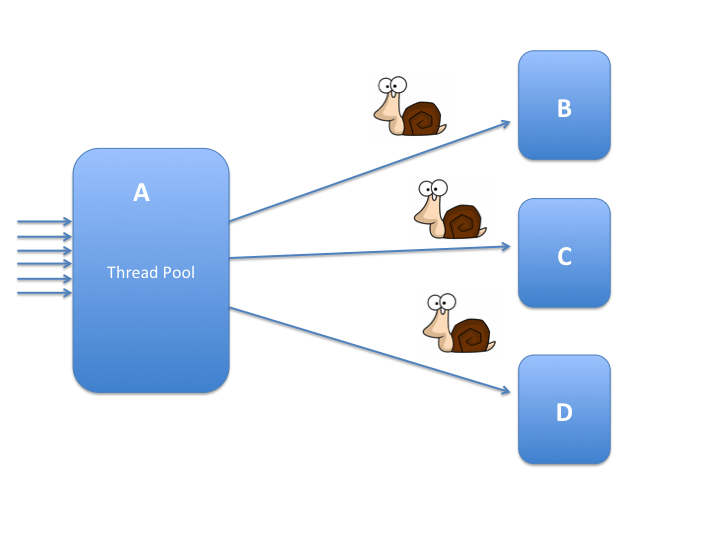
Go服务器规模:每一个请求都运行在自己的goroutine里。
让我们谈谈并发。
通信顺序进程(Hoare,1978)
并发程序作为独立进程,通过信息交流的顺序执行。
顺序执行很容易理解,异步则不是。
“不要为共亨内存通信,为通信共享内存。”
Go原理: goroutines, channels, 和 select声明.
Goroutines
Goroutines 就像轻量级线程。
它们通过小栈(tiny stacks)和按需调整运行。
Go 程序可以拥有成千上万个(goroutines)实例
使用go声明启动一个goroutines:
go f(args)
Go运行时把goroutines放进OS线程里。
不要使用线程堵塞goroutines。
Channels
Channels被定义是为了与goroutines之间通信。
c := make(chan string) // goroutine 1 c <- "hello!" // goroutine 2 s := <-c fmt.Println(s) // "hello!"
Select
select声明一个语句块来判断执行。
select {
case n := <-in:
fmt.Println("received", n)
case out <- v:
fmt.Println("sent", v)
}
只有条件成立的case块会运行。
示例:Google搜索(后端)
问: Google搜索能做些什么?
答: 提出一个问题,它可以返回一个搜索结果的页面(和一些广告)。
问: 我们怎么得到这些搜索结果?
答: 发送一个问题到网页搜索、图片搜索、YouTube(视频)、地图、新闻,稍等然后检索出结果。
我们该怎么实现它?
Google搜索 : 一个假的框架
We can simulate a Search function with a random timeout up to 100ms.
我们要模拟一个搜索函数,让它随机超时0到100毫秒。
var (
Web = fakeSearch("web")
Image = fakeSearch("image")
Video = fakeSearch("video")
)
type Search func(query string) Result
func fakeSearch(kind string) Search {
return func(query string) Result {
time.Sleep(time.Duration(rand.Intn(100)) * time.Millisecond)
return Result(fmt.Sprintf("%s result for %q\n", kind, query))
}
}
Google搜索: 测试框架
func main() {
start := time.Now()
results := Google("golang")
elapsed := time.Since(start)
fmt.Println(results)
fmt.Println(elapsed)
}
Google搜索 (串行)
Google函数获取一个查询,然后返回一个的结果集 (不一定是字符串).
Google按顺序调用Web(网页)、Image(图片)、Video(视频)并将返回加入到结果集中。
func Google(query string) (results []Result) {
results = append(results, Web(query))
results = append(results, Image(query))
results = append(results, Video(query))
return
}
Google搜索(并行)
同时执行 Web,、Image、 和Video搜索,并等待所有结果。
func方法是在query和c的地方关闭的。
func Google(query string) (results []Result) {
c := make(chan Result)
go func() { c <- Web(query) }()
go func() { c <- Image(query) }()
go func() { c <- Video(query) }()
for i := 0; i < 3; i++ {
result := <-c
results = append(results, result)
}
return
}
Google搜索 (超时)
等待慢的服务器。
没有锁,没有条件变量,没有返回值。
c := make(chan Result, 3)
go func() { c <- Web(query) }()
go func() { c <- Image(query) }()
go func() { c <- Video(query) }()
timeout := time.After(80 * time.Millisecond)
for i := 0; i < 3; i++ {
select {
case result := <-c:
results = append(results, result)
case <-timeout:
fmt.Println("timed out")
return
}
}
return
防止超时
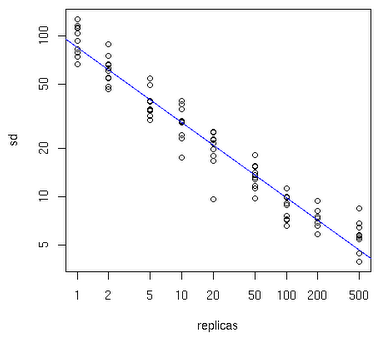
问: 如何防止丢掉慢的服务的结果?
答: 复制这个服务,然后发送请求到多个复制的服务,并使用第一个响应的结果。
func First(query string, replicas ...Search) Result {
c := make(chan Result, len(replicas))
searchReplica := func(i int) { c <- replicas[i](query) }
for i := range replicas {
go searchReplica(i)
}
return <-c
}
使用First函数
func main() {
start := time.Now()
result := First("golang",
fakeSearch("replica 1"),
fakeSearch("replica 2"))
elapsed := time.Since(start)
fmt.Println(result)
fmt.Println(elapsed)
}
Google搜索 (复制)
使用复制的服务以减少多余延迟。
c := make(chan Result, 3)
go func() { c <- First(query, Web1, Web2) }()
go func() { c <- First(query, Image1, Image2) }()
go func() { c <- First(query, Video1, Video2) }()
timeout := time.After(80 * time.Millisecond)
for i := 0; i < 3; i++ {
select {
case result := <-c:
results = append(results, result)
case <-timeout:
fmt.Println("timed out")
return
}
}
return
其他
没有锁,没有条件变量,没有调用。
总结
经过一些简单转换,我们使用 Go 的并发原语来转换一个
- 慢
- 顺序性的
- 故障敏感的
程序为一个
- 快
- 并发
- 可复用的
- 健壮的
工具
Go 有很多强大的工具
- gofmt 和 goimports
- The go tool
- godoc
- IDE 和编辑器支持
这语言就是为工具链设计的。
gofmt 和 goimports
Gofmt 可以自动格式化代码,没有选项。
Goimports 基于你的工作空间更新导入声明
大部分人可以安全的使用这些工具。
The go tool
The go tool 可以在一个传统目录布局中用源代码构建 Go 程序。不需要 Makefiles 或者其他配置。
匹配这些工具及其依赖,然后进行构建,安装:
% go get golang.org/x/tools/cmd/present
运行:
% present
godoc
为世界上所有的开源 Go 代码生成文档:
IDE 和编辑器支持
Eclipse, IntelliJ, emacs, vim 等等:
- gofmt
- goimports
- godoclookups
- code completion
- code navigation
但是没有 “Go IDE”.
Go 工具无处不在。
Go 的下一步计划
Go 路线在线查看
大量的学习资料
完美的社区
Thank you
Sameer Ajmani
Tech Lead Manager, Go team
from:http://www.oschina.net/translate/go-for-java-programmers-ppt