Overload control for scaling WeChat microservices Zhou et al., SoCC’18
There are two reasons to love this paper. First off, we get some insights into the backend that powers WeChat; and secondly the authors share the design of the battle hardened overload control system DAGOR that has been in production at WeChat for five years. This system has been specifically designed to take into account the peculiarities of microservice architectures. If you’re looking to put a strategy in place for your own microservices, you could do a lot worse than start here.
WeChat
The WeChat backend at this point consists of over 3000 mobile services, including instant messaging, social networking, mobile payment, and third-party authorization. The platform sees between  external requests per day. Each such request can triggers many more internal microservice requests, such that the WeChat backend as a whole needs to handle hundreds of millions of requests per second.
external requests per day. Each such request can triggers many more internal microservice requests, such that the WeChat backend as a whole needs to handle hundreds of millions of requests per second.
WeChat’s microservice system accommodates more than 3000 services running on over 20,000 machines in the WeChat business system, and these numbers keep increasing as WeChat is becoming immensely popular… As WeChat is ever actively evolving, its microservice system has been undergoing fast iteration of service updates. For instance, from March to May in 2018, WeChat’s microservice system experienced almost a thousand changes per day on average.
WeChat classify their microservices as “Entry leap” services (front-end services receiving external requests), “Shared leap” services (middle-tier orchestration services), and “Basic services” (services that don’t fan out to any other services, and thus act as sinks for requests).
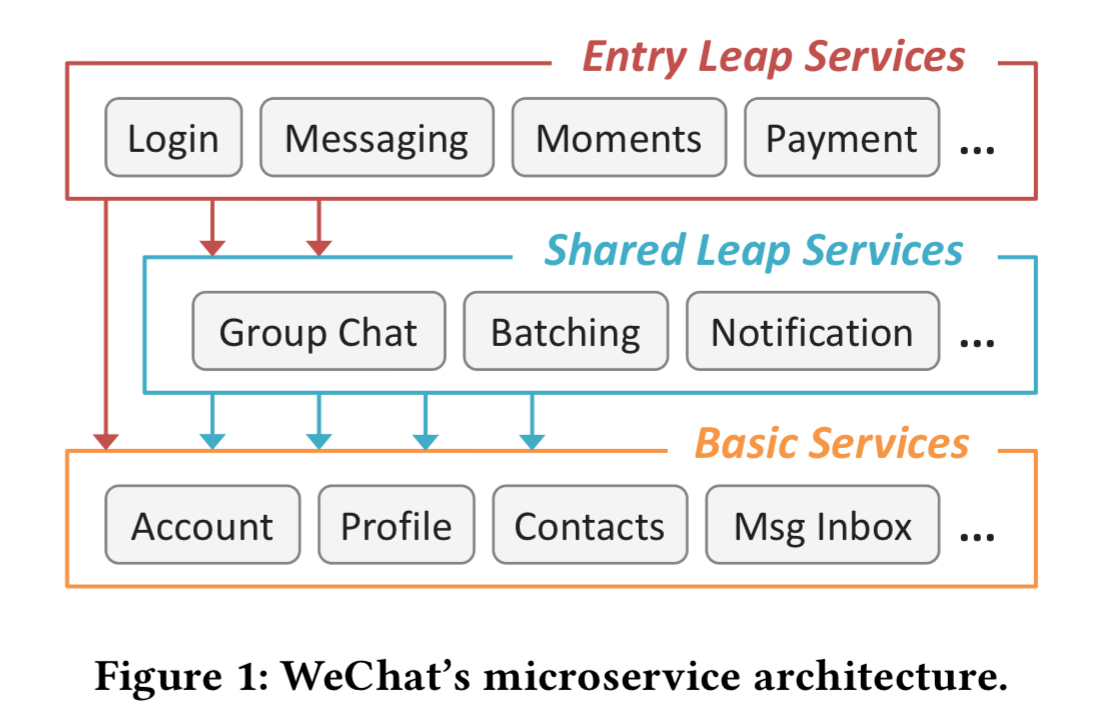
On a typical day, peak request rate is about 3x the daily average. At certain times of year (e.g. around the Chinese Lunar New Year) peak workload can rise up to 10x the daily average.
Challenges of overload control for large-scale microservice-based platforms
Overload control… is essential for large-scale online applications that need to enforce 24×7 service availability despite any unpredictable load surge.
Traditional overload control mechanisms were designed for a world with a small number of service components, a relatively narrow ‘front-door,’ and trivial dependencies.
… modern online services are becoming increasingly complex in their architecture and dependencies, far beyond what traditional overload control was designed for.
- With no single entry point for service requests sent to the WeChat backend, the conventional approach of centralized load monitoring at a global entry point (gateway) is not applicable.
- The service invocation graph for a particular request may depend on request-specific data and service parameters, even for requests of the same type. So when a particular service becomes overload it is very difficult to determine what types of requests should be dropped to mitigate the situation.
- Excessive request aborts (especially when deeper in the call graph or later in the request processing) waste computational resources and affect user experience due to high latency.
- Since the service DAG is extremely complex and continuously evolving, the maintenance cost and system overhead for effective cross-service coordination is too high.
Since one service may make multiple requests to a service it depends on, and may also make requests to multiple backend services, we have to take extra care with overload controls. The authors coin the term subsequent overload for the cases where more than one overloaded service is invoked, or a single overloaded service is invoked multiple times.
Subsequent overload raises challenges for effective overload control. Intuitively, performing load shedding at random when a service becomes overloaded can sustain the system with a saturated throughput. However, subsequent overload may greatly degrade system throughput beyond that intended…
Consider a simple scenario where service A invokes service B twice. If B starts rejecting half of all incoming requests, A’s probability of success drops to 0.25.
DAGOR overview
WeChat’s overload control system is called DAGOR. It aims to provide overload control to all services and thus is designed to be service agnostic. Overload control runs at the granularity of an individual machine, since centralised global coordination is too expensive. However, it does incorporate a lightweight collaborative inter-machine protocol which is needed to handle subsequent overload situations. Finally, DAGOR should sustain the best-effort success rate of a service when load shedding becomes inevitable due to overload. Computational resources (e.g. CPU, I/O) spent on failed service tasks should be minimised.
We have two basic tasks to address: detecting an overload situation, and deciding what to do about it once detected.
Overload detection
For overload detection, DAGOR uses the average waiting time of requests in the pending queue (i.e., queuing time). Queuing time has the advantage of negating the impact of delays lower down in the call-graph (compared to e.g. request processing time). Request processing time can increase even when the local server itself is not overloaded. DAGOR uses window-based monitoring, where a window is one second or 2000 requests, whichever comes first. WeChat clearly run a tight ship:
For overload detection, given the default timeout of each service task being 500ms in WeChat, the threshold of the average request queuing time to indicate server overload is set to 20ms. Such empirical configurations have been applied in the WeChat business system for more than five years with its effectiveness proven by the system robustness with respect to WeChat business activities.
Admission control
Once overload is detected, we have to decide what to do about it. Or to put things more bluntly, which requests we’re going to drop. The first observation is that not all requests are equal:
The operation log of WeChat shows that when WeChat Pay and Instant Messaging experience a similar period of service unavailability, user complaints against the WeChat Pay service are 100x those against the Instant Messaging service.
To deal with this in a service agnostic way, every request is assigned a business priority when it first enters the system. This priority flows with all downstream requests. Business priority for a user request is determined by the type of action requested. Although there are hundreds of entry points, only a few tens have explicit priority, all the others having a default (lower) priority. The priorities are maintained in a replicated hashtable.
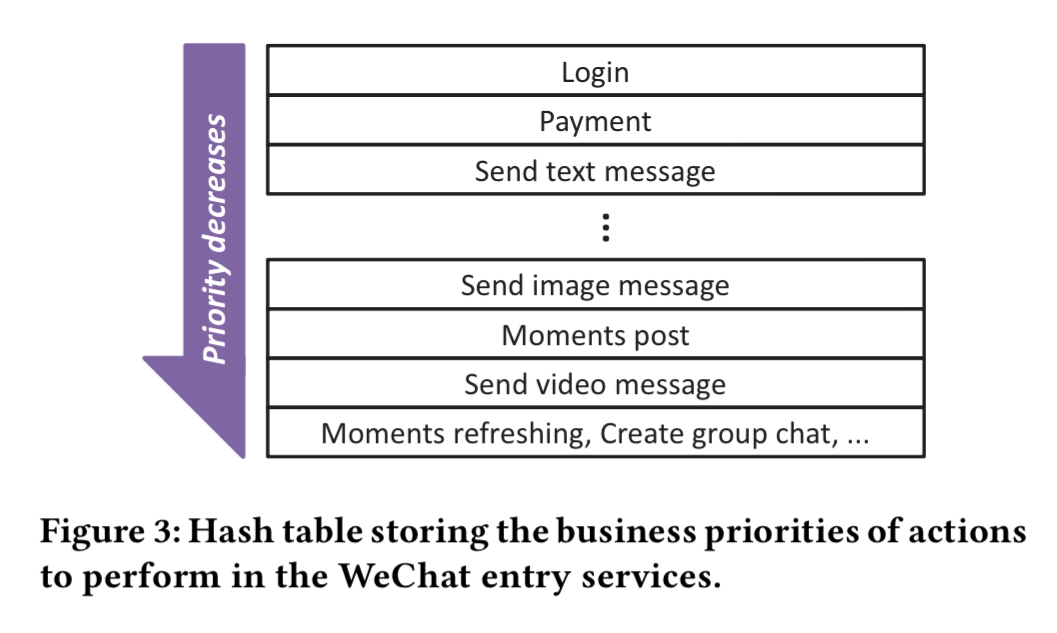
When overload control is set to business priority level n, all requests from levels n+1 will be dropped. That’s great for mixed workloads, but suppose we have a flood of Payment requests, all at the same priority (e.g. p). The system will become overloaded, and hence move the overload threshold to p-1, when it will become lightly loaded again. Once light load is detected, the overload threshold is incremented to p again, and once more we are in overload. To stop this flip-flipping when overloaded with requests at the same priority level, we need a level of granularity finer than business priority.
WeChat has a neat solution to this. It adds a second layer of admission control based on user-id.
User priority is dynamically generated by the entry service through a hash function that takes the user ID as an argument. Each entry service changes its hash function every hour. As a consequence, requests from the same user are likely to be assigned to the same user priority within one hour, but different user priorities across hours.
This provides fairness while also giving an individual user a consistent experience across a relatively long period of time. It also helps with the subsequent overload problem since requests from a user assigned high priority are more likely to be honoured all the way through the call graph.
Combining business priority and user priority gives a compound admission level with 128 levels of user priority per business priority level.
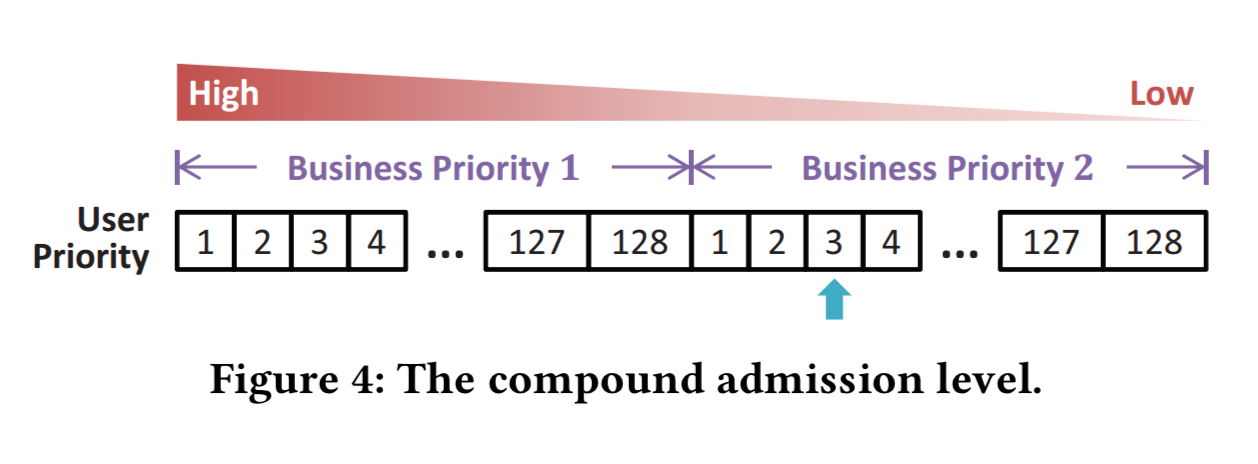
With each admission level of business priority having 128 levels of user priority, the resulting number of compound admission levels is in the tens of thousands. Adjustment of the compound admission level is at the granule of user priority.
There’s a nice sidebar on why using session ID instead of user ID doesn’t work: you end up training users to log out and then log back in again when they’re experiencing poor service, and now you have a login storm on top of your original overload problem!
DAGOR maintains a histogram of requests at each server to track the approximate distribution of requests over admission priorities. When overload is detected in a window period, DAGOR moves to the first bucket that will decrease expected load by 5%. With no overload, it moves to the first bucket that will increase expected load by 1%.
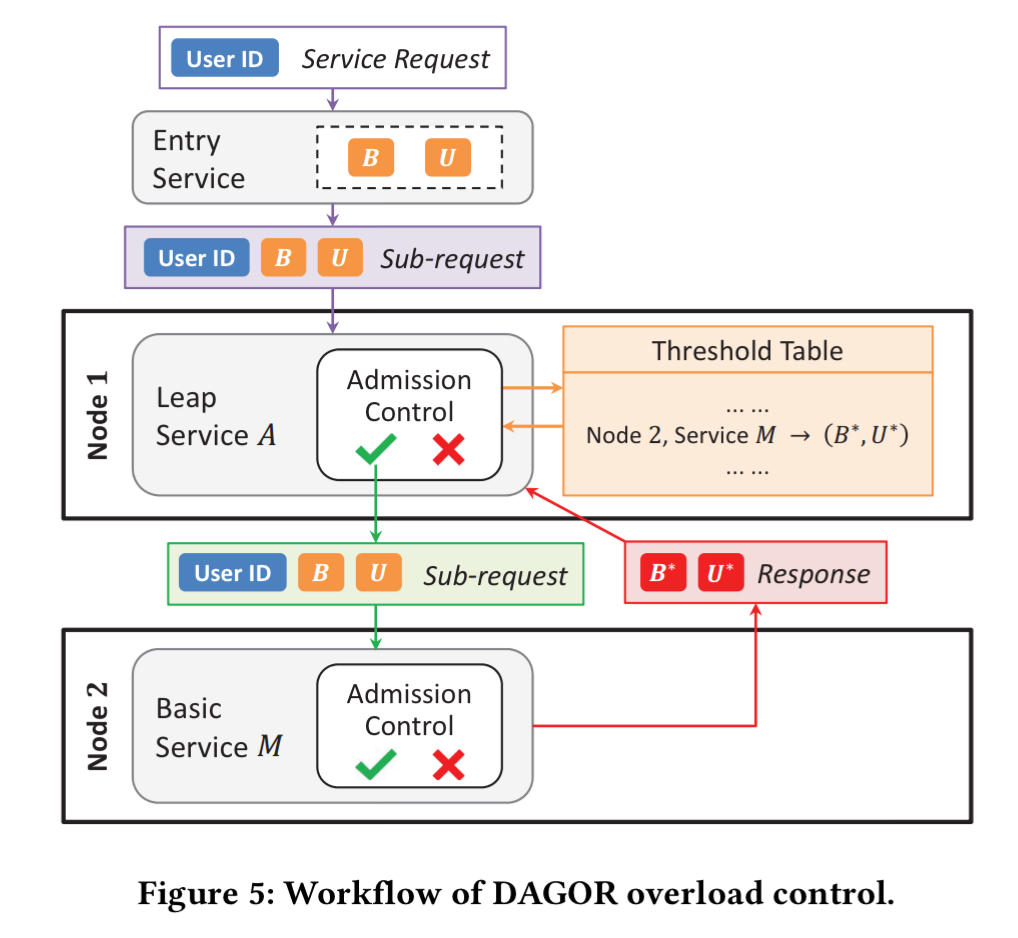
A server piggy-backs its current admission level on each response message sent to upstream servers. In this way an upstream server learns the current admission control setting of a downstream service, and can perform local admission control on the request before even sending it.
End-to-end therefore, the DAGOR overload control system looks like this:
Experiments
The best testimony to the design of DAGOR is that it’s been working well in production at WeChat for five years. That doesn’t provide the requisite graphs for an academic paper though, so we also get a set of simulation experiments. The following chart highlights the benefits of overload control based on queuing time rather than response time. The benefits are most pronounced in situations of subsequent overload (chart (b)).

Compared to CoDel and SEDA, DAGOR exhibits a 50% higher request success rate with subsequent overloading when making one subsequent call. The benefits are greater the higher the number of subsequent requests:
Finally, in terms of fairness CoDel can be seen to favour services with smaller fan-out to overloaded services when under stress, whereas DAGOR manifests roughly the same success rate across a variety of requests.
Three lessons for your own systems
Even if you don’t use DAGOR exactly as described, the authors conclude with three valuable lessons to take into consideration:
- Overload control in a large-scale microservice architecture must be decentralized and autonomous in each service
- Overload control should take into account a variety of feedback mechanisms (e.g. DAGOR’s collaborative admission control) rather than relying solely on open-loop heuristics
- Overload control design should be informed by profiling the processing behaviour of your actual workloads.
中文版链接: https://www.tuicool.com/articles/aYJjMvN
from:https://blog.acolyer.org/2018/11/16/overload-control-for-scaling-wechat-microservices/








































